参考 :
https://mycyberuniverse.com/how-fix-node-gyp-rebuild-fail-no-xcode-clt.html
重新安装 Command Line Tools for Xcode 就好了
参考 :
https://mycyberuniverse.com/how-fix-node-gyp-rebuild-fail-no-xcode-clt.html
重新安装 Command Line Tools for Xcode 就好了
现实中我们经常会用上扫码登录的方式,可以借助微信、qq等oauth2认证方式,也可以通过APP
实现扫码登录。那么现在我们介绍下通过app实现扫码登录的一系列原理,及实现的过程。

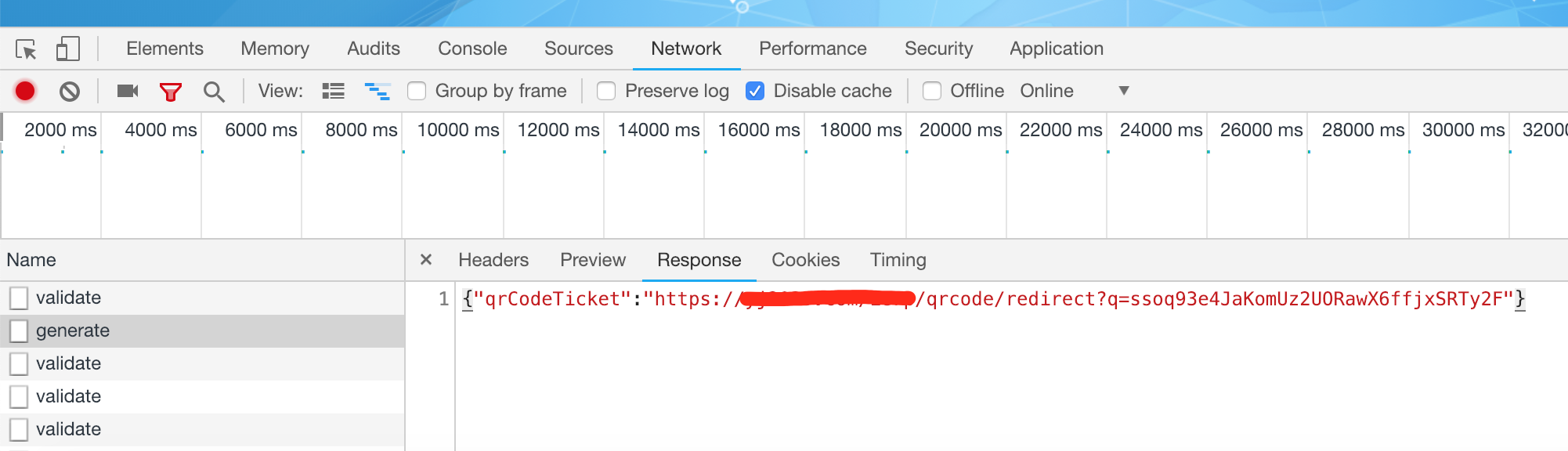
返回结果可以是单独ticket串,也可以是url(方便通过其他扫码工具扫描后转向公司宣传页面)
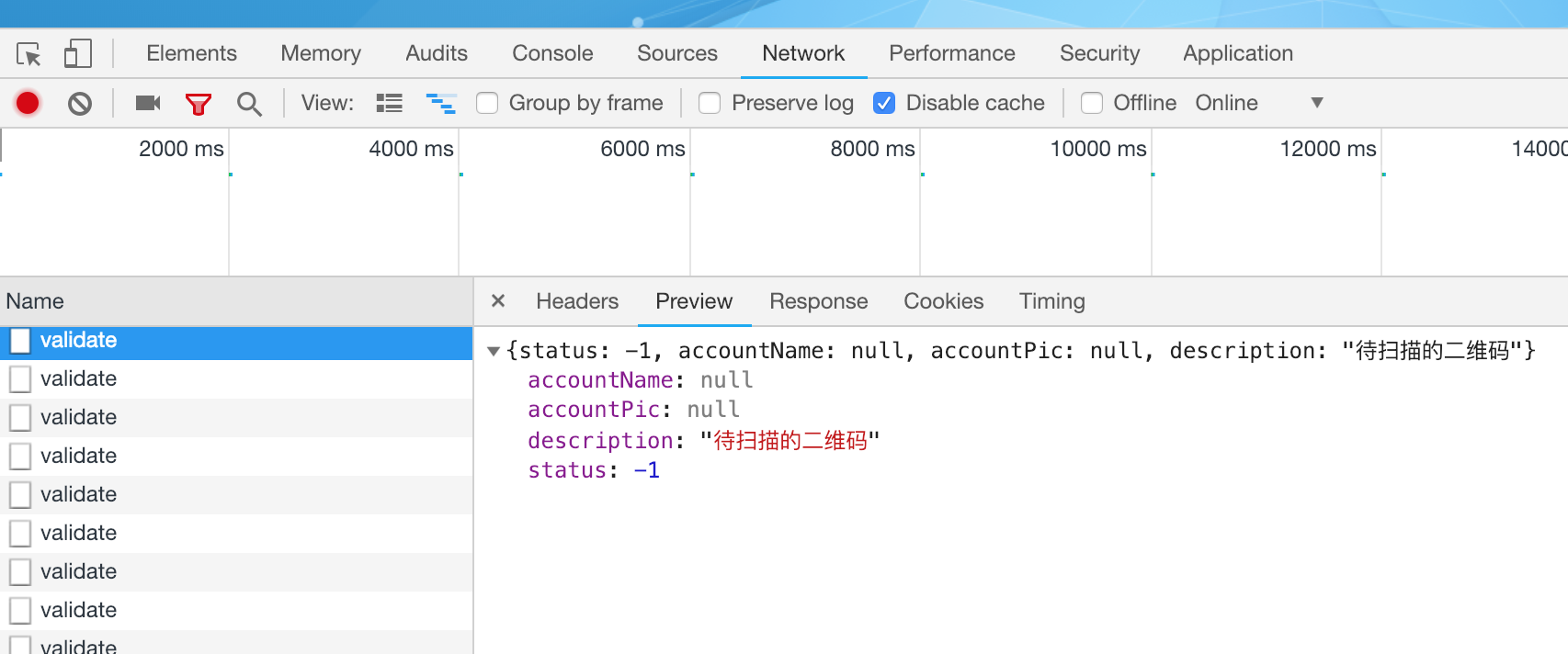
每隔1~2秒轮循环后台扫描结果。
代码参考:1
2
3
4
5
6
7
8
9
10
11
12
13
(value = "/qrcode/generate",method = RequestMethod.POST)
public Map<String,String> generateQrCode(HttpServletRequest request){
String qrcode = qrcodeService.createQrcode();
//二维码登录ticket 放入session中
request.getSession().setAttribute(QRCODE_TICKET_KEY,qrcode);
Map<String,String> map = new HashMap<>();
map.put(QRCODE_TICKET_KEY,domainUrl+"ierp/qrcode/redirect?q="+qrcode);
return map;
}
$qrcodeService#createQrcode()
1 | /** |
参考代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28/**
* 获取二维码的扫码状态
* @param qrCodeTicket
* @return
*/
public QrcodeStatus getQrcodeStatus(String qrCodeTicket){
String value = redisTemplate.boundValueOps(QRCODE_REDIS_KEY_PREFIX + qrCodeTicket).get();
if(value==null||"".equals(value)){
return new QrcodeStatus(-2,"无效的二维码");
}else if(value.equals("unknown")){
return new QrcodeStatus(-1,"待扫描的二维码");
}else{
try {
JsonNode jsonNode = objectMapper.readValue(value, JsonNode.class);
String accountName = jsonNode.path("accountName").asText();
String accountPic = jsonNode.path("accountPic").asText();
boolean confirm = jsonNode.path("confirm").asBoolean();
if(confirm){
return new QrcodeStatus(1,accountName,accountPic,"确认登录");
}else {
return new QrcodeStatus(0,accountName,accountPic,"未确认登录,用来显示头像");
}
} catch (IOException e) {
e.printStackTrace();
}
return new QrcodeStatus(-3,"未知错误");
}
}
1 | ("扫码登录") |
1 | ("/qrcode/redirect") |
那么这个二维码就会即起到了扫码登陆的作用,也起到了扫描下载app,或者进入宣传网站的作用。可谓一举多得。
在spring boot工程的 application.properties 文件中加入:1
spring.jpa.properties.hibernate.ejb.interceptor=全类名例如:[com.ierp.jpa.interceptors.TraceInterceptor]
对应的 TraceInterceptor 继承 一个hibernate的 空拦截器[org.hibernate.EmptyInterceptor] 即可
文件内容:
1 | [mongodb-org-3.2] |
1 | sudo yum install -y mongodb-org |
1 | sudo service mongod start |
在启动mongodb之前可以配置下mongodb的db path 等.
创建一个目录用来保存log 和db 文件 ,这里以 /www/mongodb/ 为例
注意: 要赋予该目录相应的权限1
chown -R mongod.mongod /www/mongodb
好了, 可以启动mongodb服务了.
1 | sudo service mongod start |
1 | mongodump -d {数据库名} -o {要保存的目录} |
例如:
mongodump -d ddc -o /mnt/wwwroot/ddc.dmp
1 | mongorestore -d {数据库名} {备份的数据库目录} |
例如:
mongorestore -d ddc /mnt/wwwroot/ddc.dmp/ddc
(转)
MySQL凭借着出色的性能、低廉的成本、丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库。虽然性能出色,但所谓“好马配好鞍”,如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位描述上看到诸如“精通MySQL”、“SQL语句优化”、“了解数据库原理”等要求。我们知道一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重。
本人从13年7月份起,一直在美团核心业务系统部做慢查询的优化工作,共计十余个系统,累计解决和积累了上百个慢查询案例。随着业务的复杂性提升,遇到的问题千奇百怪,五花八门,匪夷所思。本文旨在以开发工程师的角度来解释数据库索引的原理和如何优化慢查询。
1 | select count(*) from task where status=2 and operator_id=20839 and operate_time>1371169729 and operate_time<1371174603 and type=2; |
系统使用者反应有一个功能越来越慢,于是工程师找到了上面的SQL。
并且兴致冲冲的找到了我,“这个SQL需要优化,给我把每个字段都加上索引”
我很惊讶,问道“为什么需要每个字段都加上索引?”
“把查询的字段都加上索引会更快”工程师信心满满
“这种情况完全可以建一个联合索引,因为是最左前缀匹配,所以operate_time需要放到最后,而且还需要把其他相关的查询都拿来,需要做一个综合评估。”
“联合索引?最左前缀匹配?综合评估?”工程师不禁陷入了沉思。
多数情况下,我们知道索引能够提高查询效率,但应该如何建立索引?索引的顺序如何?许多人却只知道大概。其实理解这些概念并不难,而且索引的原理远没有想象的那么复杂。
索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的,如果我想找到m开头的单词呢?或者ze开头的单词呢?是不是觉得如果没有索引,这个事情根本无法完成?
除了词典,生活中随处可见索引的例子,如火车站的车次表、图书的目录等。它们的原理都是一样的,通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是我们总是通过同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂许多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段……这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的,数据库实现比较复杂,数据保存在磁盘上,而为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
前面提到了访问磁盘,那么这里先简单介绍一下磁盘IO和预读,磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500 -MIPS的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行40万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。下图是计算机硬件延迟的对比图,供大家参考:
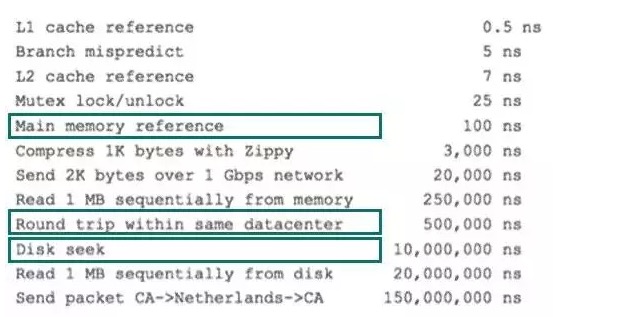
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
前面讲了生活中索引的例子,索引的基本原理,数据库的复杂性,又讲了操作系统的相关知识,目的就是让大家了解,任何一种数据结构都不是凭空产生的,一定会有它的背景和使用场景,我们现在总结一下,我们需要这种数据结构能够做些什么,其实很简单,那就是:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生。
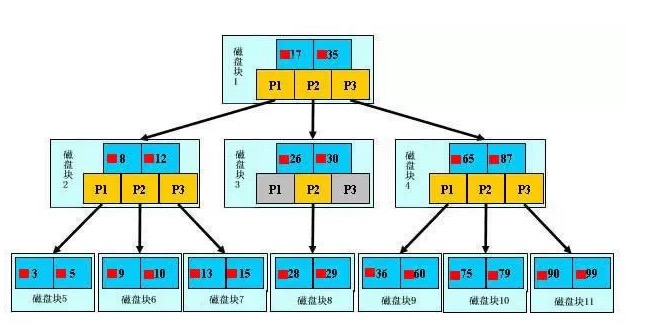
如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
1.通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
2.当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
关于MySQL索引原理是比较枯燥的东西,大家只需要有一个感性的认识,并不需要理解得非常透彻和深入。我们回头来看看一开始我们说的慢查询,了解完索引原理之后,大家是不是有什么想法呢?先总结一下索引的几大基本原则
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
根据最左匹配原则,最开始的sql语句的索引应该是status、operator_id、type、operate_time的联合索引;其中status、operator_id、type的顺序可以颠倒,所以我才会说,把这个表的所有相关查询都找到,会综合分析;
比如还有如下查询
1 | select * from task where status = 0 and type = 12 limit 10; |
那么索引建立成(status,type,operator_id,operate_time)就是非常正确的,因为可以覆盖到所有情况。这个就是利用了索引的最左匹配的原则
关于explain命令相信大家并不陌生,具体用法和字段含义可以参考官网explain-output,这里需要强调rows是核心指标,绝大部分rows小的语句执行一定很快(有例外,下面会讲到)。所以优化语句基本上都是在优化rows。
0.先运行看看是否真的很慢,注意设置SQL_NO_CACHE
1.where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
2.explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
3.order by limit 形式的sql语句让排序的表优先查
4.了解业务方使用场景
5.加索引时参照建索引的几大原则
6.观察结果,不符合预期继续从0分析
下面几个例子详细解释了如何分析和优化慢查询
很多情况下,我们写SQL只是为了实现功能,这只是第一步,不同的语句书写方式对于效率往往有本质的差别,这要求我们对mysql的执行计划和索引原则有非常清楚的认识,请看下面的语句
1 | select |
0.先运行一下,53条记录 1.87秒,又没有用聚合语句,比较慢
1 | 53 rows in set (1.87 sec) |
1.explain
1 | +----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+ |
简述一下执行计划,首先mysql根据idx_last_upd_date索引扫描cm_log表获得379条记录;然后查表扫描了63727条记录,分为两部分,derived表示构造表,也就是不存在的表,可以简单理解成是一个语句形成的结果集,后面的数字表示语句的ID。derived2表示的是ID = 2的查询构造了虚拟表,并且返回了63727条记录。我们再来看看ID = 2的语句究竟做了写什么返回了这么大量的数据,首先全表扫描employee表13317条记录,然后根据索引emp_certificate_empid关联emp_certificate表,rows = 1表示,每个关联都只锁定了一条记录,效率比较高。获得后,再和cm_log的379条记录根据规则关联。从执行过程上可以看出返回了太多的数据,返回的数据绝大部分cm_log都用不到,因为cm_log只锁定了379条记录。
如何优化呢?可以看到我们在运行完后还是要和cm_log做join,那么我们能不能之前和cm_log做join呢?仔细分析语句不难发现,其基本思想是如果cm_log的ref_table是EmpCertificate就关联emp_certificate表,如果ref_table是Employee就关联employee表,我们完全可以拆成两部分,并用union连接起来,注意这里用union,而不用union all是因为原语句有“distinct”来得到唯一的记录,而union恰好具备了这种功能。如果原语句中没有distinct不需要去重,我们就可以直接使用union all了,因为使用union需要去重的动作,会影响SQL性能。
优化过的语句如下
1 | select |
4.不需要了解业务场景,只需要改造的语句和改造之前的语句保持结果一致
5.现有索引可以满足,不需要建索引
6.用改造后的语句实验一下,只需要10ms 降低了近200倍!
1 | +----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+ |
举这个例子的目的在于颠覆我们对列的区分度的认知,一般上我们认为区分度越高的列,越容易锁定更少的记录,但在一些特殊的情况下,这种理论是有局限性的
1 | select |
0.先看看运行多长时间,951条数据6.22秒,真的很慢
1 | 951 rows in set (6.22 sec) |
1.先explain,rows达到了361万,type = ALL表明是全表扫描
1 | +----+-------------+-------+------+---------------+------+---------+------+---------+-------------+ |
2.所有字段都应用查询返回记录数,因为是单表查询 0已经做过了951条
3.让explain的rows 尽量逼近951
看一下accurate_result = 1的记录数
1 | select count(*),accurate_result from stage_poi group by accurate_result; |
我们看到accurate_result这个字段的区分度非常低,整个表只有-1,0,1三个值,加上索引也无法锁定特别少量的数据
再看一下sync_status字段的情况
1 | select count(*),sync_status from stage_poi group by sync_status; |
同样的区分度也很低,根据理论,也不适合建立索引
问题分析到这,好像得出了这个表无法优化的结论,两个列的区分度都很低,即便加上索引也只能适应这种情况,很难做普遍性的优化,比如当sync_status 0、3分布的很平均,那么锁定记录也是百万级别的
4.找业务方去沟通,看看使用场景。业务方是这么来使用这个SQL语句的,每隔五分钟会扫描符合条件的数据,处理完成后把sync_status这个字段变成1,五分钟符合条件的记录数并不会太多,1000个左右。了解了业务方的使用场景后,优化这个SQL就变得简单了,因为业务方保证了数据的不平衡,如果加上索引可以过滤掉绝大部分不需要的数据
5.根据建立索引规则,使用如下语句建立索引
1 | alter table stage_poi add index idx_acc_status(accurate_result,sync_status); |
6.观察预期结果,发现只需要200ms,快了30多倍。
1 | 952 rows in set (0.20 sec) |
我们再来回顾一下分析问题的过程,单表查询相对来说比较好优化,大部分时候只需要把where条件里面的字段依照规则加上索引就好,如果只是这种“无脑”优化的话,显然一些区分度非常低的列,不应该加索引的列也会被加上索引,这样会对插入、更新性能造成严重的影响,同时也有可能影响其它的查询语句。所以我们第4步调差SQL的使用场景非常关键,我们只有知道这个业务场景,才能更好地辅助我们更好的分析和优化查询语句。
无法优化的语句
1 | select |
还是几个步骤
0.先看语句运行多长时间,10条记录用了13秒,已经不可忍受
1 | 10 rows in set (13.06 sec) |
1.explain
1 | +----+-------------+-------+--------+-------------------------------------+-------------------------+---------+--------------------------+------+----------------------------------------------+ |
从执行计划上看,mysql先查org_emp_info表扫描8849记录,再用索引idx_userid_status关联branch_user表,再用索引idx_branch_id关联contact_branch表,最后主键关联contact表。
rows返回的都非常少,看不到有什么异常情况。我们在看一下语句,发现后面有order by + limit组合,会不会是排序量太大搞的?于是我们简化SQL,去掉后面的order by 和 limit,看看到底用了多少记录来排序
1 | select |
发现排序之前居然锁定了778878条记录,如果针对70万的结果集排序,将是灾难性的,怪不得这么慢,那我们能不能换个思路,先根据contact的created_time排序,再来join会不会比较快呢?
于是改造成下面的语句,也可以用straight_join来优化
1 | select |
验证一下效果 预计在1ms内,提升了13000多倍!
1 | 10 rows in set (0.00 sec) |
本以为至此大工告成,但我们在前面的分析中漏了一个细节,先排序再join和先join再排序理论上开销是一样的,为何提升这么多是因为有一个limit!大致执行过程是:mysql先按索引排序得到前10条记录,然后再去join过滤,当发现不够10条的时候,再次去10条,再次join,这显然在内层join过滤的数据非常多的时候,将是灾难的,极端情况,内层一条数据都找不到,mysql还傻乎乎的每次取10条,几乎遍历了这个数据表!
用不同参数的SQL试验下
1 | select |
2 min 18.99 sec!比之前的情况还糟糕很多。由于mysql的nested loop机制,遇到这种情况,基本是无法优化的。这条语句最终也只能交给应用系统去优化自己的逻辑了。
通过这个例子我们可以看到,并不是所有语句都能优化,而往往我们优化时,由于SQL用例回归时落掉一些极端情况,会造成比原来还严重的后果。所以,第一:不要指望所有语句都能通过SQL优化,第二:不要过于自信,只针对具体case来优化,而忽略了更复杂的情况。
慢查询的案例就分析到这儿,以上只是一些比较典型的案例。我们在优化过程中遇到过超过1000行,涉及到16个表join的“垃圾SQL”,也遇到过线上线下数据库差异导致应用直接被慢查询拖死,也遇到过varchar等值比较没有写单引号,还遇到过笛卡尔积查询直接把从库搞死。再多的案例其实也只是一些经验的积累,如果我们熟悉查询优化器、索引的内部原理,那么分析这些案例就变得特别简单了。
本文以一个慢查询案例引入了MySQL索引原理、优化慢查询的一些方法论;并针对遇到的典型案例做了详细的分析。其实做了这么长时间的语句优化后才发现,任何数据库层面的优化都抵不上应用系统的优化,同样是MySQL,可以用来支撑Google/FaceBook/Taobao应用,但可能连你的个人网站都撑不住。套用最近比较流行的话:“查询容易,优化不易,且写且珍惜!”
参考文献如下:
1.《高性能MySQL》
2.《数据结构与算法分析》
出处:美团技术博客
链接:http://tech.meituan.com/mysql-index.html
使用一般的new方法来创建线程有什么问题呢?一般的new线程的方式一般要给出一个实现了Runnable接口的执行类,在其中重写run()方法,然后再在将这个执行类的对象传给线程以完成初始化,这个过程中线程的定义和执行过程其实是杂糅在一起了,而且每次new一个新的线程出来在资源上很有可能会产生不必要的消耗,因此我们通过多线程执行框架来解决这两个问题,其一可以分离线程的定义和执行过程,其二可以通过线程池来动态地管理线程以减小不必要的资源开销。
将要多线程执行的任务封装为一个Runnable对象,将其传给一个执行框架Executor对象, Executor从线程池中选择线程执行工作任务。
创建多线程框架对象调用线程执行任务
我们通常通过Executors类的一些静态方法来实例化Executor或ThreadPoolExecutor对象:
比如Executor对象来执行:
1 | public class ThreadTest { |
比如线程池的Executor对象来执行:
1 | public class ThreadTest { |
实现了Runnable接口的执行类虽然可以在run()方法里写入执行体,但是无法返回结果值,因为run()方法是void型的,而Callable接口解决了这个问题,在继承了Callable接口的执行类中重写call()方法可以设置返回值,当Executor对象使用submit()函数提交执行类的时候会由线程池里的线程来运行,运行得到的返回值可以使用Future
1.invokeAny():
1 | public class ThreadTest { |
2.invokeAll():
1 | public class ThreadTest { |
使用Executor的schedule()函数族来调度线程池中的线程来执行callable执行类对象中的call()定时任务:
1 | public class ThreadTest { |
示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42location = / {
# 精确匹配 / ,主机名后面不能带任何字符串
[ configuration A ]
}
location / {
# 因为所有的地址都以 / 开头,所以这条规则将匹配到所有请求
# 但是正则和最长字符串会优先匹配
[ configuration B ]
}
location /documents/ {
# 匹配任何以 /documents/ 开头的地址,匹配符合以后,还要继续往下搜索
# 只有后面的正则表达式没有匹配到时,这一条才会采用这一条
[ configuration C ]
}
location ~ /documents/Abc {
# 匹配任何以 /documents/ 开头的地址,匹配符合以后,还要继续往下搜索
# 只有后面的正则表达式没有匹配到时,这一条才会采用这一条
[ configuration CC ]
}
location ^~ /images/ {
# 匹配任何以 /images/ 开头的地址,匹配符合以后,停止往下搜索正则,采用这一条。
[ configuration D ]
}
location ~* \.(gif|jpg|jpeg)$ {
# 匹配所有以 gif,jpg或jpeg 结尾的请求
# 然而,所有请求 /images/ 下的图片会被 config D 处理,因为 ^~ 到达不了这一条正则
[ configuration E ]
}
location /images/ {
# 字符匹配到 /images/,继续往下,会发现 ^~ 存在
[ configuration F ]
}
location /images/abc {
# 最长字符匹配到 /images/abc,继续往下,会发现 ^~ 存在
# F与G的放置顺序是没有关系的
[ configuration G ]
}
location ~ /images/abc/ {
# 只有去掉 config D 才有效:先最长匹配 config G 开头的地址,继续往下搜索,匹配到这一条正则,采用
[ configuration H ]
}
location ~* /js/.*/\.js
顺序 no优先级:(location =) > (location 完整路径) > (location ^~ 路径) > (location ~,~* 正则顺序) > (location 部分起始路径) > (/)
上面的匹配结果
按照上面的location写法,以下的匹配示例成立:
1 | 所以实际使用中,个人觉得至少有三个匹配规则定义,如下: |
参考:
http://tengine.taobao.org/book/chapter_02.html
http://nginx.org/en/docs/http/ngx_http_rewrite_module.html
rewrite功能就是,使用nginx提供的全局变量或自己设置的变量,结合正则表达式和标志位实现url重写以及重定向。rewrite只能放在server{},location{},if{}中,并且只能对域名后边的除去传递的参数外的字符串起作用,例如 http://seanlook.com/a/we/index.php?id=1&u=str 只对/a/we/index.php重写。语法rewrite regex replacement [flag];
如果相对域名或参数字符串起作用,可以使用全局变量匹配,也可以使用proxy_pass反向代理。
表明看rewrite和location功能有点像,都能实现跳转,主要区别在于rewrite是在同一域名内更改获取资源的路径,而location是对一类路径做控制访问或反向代理,可以proxy_pass到其他机器。很多情况下rewrite也会写在location里,它们的执行顺序是:
如果其中某步URI被重写,则重新循环执行1-3,直到找到真实存在的文件;循环超过10次,则返回500 Internal Server Error错误。
因为301和302不能简单的只返回状态码,还必须有重定向的URL,这就是return指令无法返回301,302的原因了。这里 last 和 break 区别有点难以理解:
if判断指令
语法为if(condition){…},对给定的条件condition进行判断。如果为真,大括号内的rewrite指令将被执行,if条件(conditon)可以是如下任何内容:
-f和!-f用来判断是否存在文件
-d和!-d用来判断是否存在目录
-e和!-e用来判断是否存在文件或目录
-x和!-x用来判断文件是否可执行
例如:
1 | if ($http_user_agent ~ MSIE) { |
全局变量
下面是可以用作if判断的全局变量
例:http://localhost:88/test1/test2/test.php
$host:localhost
$server_port:88
$request_uri:http://localhost:88/test1/test2/test.php
$document_uri:/test1/test2/test.php
$document_root:/var/www/html
$request_filename:/var/www/html/test1/test2/test.php
小括号()之间匹配的内容,可以在后面通过$1来引用,$2表示的是前面第二个()里的内容。正则里面容易让人困惑的是\转义特殊字符。
例1:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31http {
# 定义image日志格式
log_format imagelog '[$time_local] ' $image_file ' ' $image_type ' ' $body_bytes_sent ' ' $status;
# 开启重写日志
rewrite_log on;
server {
root /home/www;
location / {
# 重写规则信息
error_log logs/rewrite.log notice;
# 注意这里要用‘’单引号引起来,避免{}
rewrite '^/images/([a-z]{2})/([a-z0-9]{5})/(.*)\.(png|jpg|gif)$' /data?file=$3.$4;
# 注意不能在上面这条规则后面加上“last”参数,否则下面的set指令不会执行
set $image_file $3;
set $image_type $4;
}
location /data {
# 指定针对图片的日志格式,来分析图片类型和大小
access_log logs/images.log mian;
root /data/images;
# 应用前面定义的变量。判断首先文件在不在,不在再判断目录在不在,如果还不在就跳转到最后一个url里
try_files /$arg_file /image404.html;
}
location = /image404.html {
# 图片不存在返回特定的信息
return 404 "image not found\n";
}
}
对形如/images/ef/uh7b3/test.png的请求,重写到/data?file=test.png,于是匹配到location /data,先看/data/images/test.png文件存不存在,如果存在则正常响应,如果不存在则重写tryfiles到新的image404 location,直接返回404状态码。
例2:1
rewrite ^/images/(.*)_(\d+)x(\d+)\.(png|jpg|gif)$ /resizer/$1.$4?width=$2&height=$3? last;
对形如/images/bla_500x400.jpg的文件请求,重写到/resizer/bla.jpg?width=500&height=400地址,并会继续尝试匹配location。
例3:
见 ssl部分页面加密 。
参考
http://www.nginx.cn/216.html
http://www.ttlsa.com/nginx/nginx-rewriting-rules-guide/
老僧系列nginx之rewrite规则快速上手
http://fantefei.blog.51cto.com/2229719/919431
按照OSI网络分层模型,IP是网络层协议,TCP是传输层协议,而HTTP和MQTT是应用层的协议。在这三者之间, TCP是HTTP和MQTT底层的协议。大家对HTTP很熟悉,这里简要介绍下MQTT。MQTT(Message Queuing Telemetry Transport,消息队列遥测传输)是IBM开发的一个即时通讯协议,有可能成为物联网的重要组成部分。该协议支持所有平台,几乎可以把所有联网物品和外部连接起来,被用来当做传感器的通信协议。
HTTP协议经过多年的使用,发现了一些不足,主要是性能方面的,包括:
HTTP的连接问题,HTTP客户端和服务器之间的交互是采用请求/应答模式,在客户端请求时,会建立一个HTTP连接,然后发送请求消息,服务端给出应答消息,然后连接就关闭了。(后来的HTTP1.1支持持久连接)
因为TCP连接的建立过程是有开销的,如果使用了SSL/TLS开销就更大。
在浏览器里,一个网页包含许多资源,包括HTML,CSS,JavaScript,图片等等,这样在加载一个网页时要同时打开连接到同一服务器的多个连接。
HTTP消息头问题,现在的客户端会发送大量的HTTP消息头,由于一个网页可能需要50-100个请求,就会有相当大的消息头的数据量。
HTTP通信方式问题,HTTP的请求/应答方式的会话都是客户端发起的,缺乏服务器通知客户端的机制,在需要通知的场景,如聊天室,游戏,客户端应用需要不断地轮询服务器。
而 WebSocket是从不同的角度来解决这些不足中的一部分。还有其他技术也在针对这些不足提出改进。
WebSocket则提供使用一个TCP连接进行双向通讯的机制,包括网络协议和API,以取代网页和服务器采用HTTP轮询进行双向通讯的机制。
本质上来说,WebSocket是不限于HTTP协议的,但是由于现存大量的HTTP基础设施,代理,过滤,身份认证等等,WebSocket借用HTTP和HTTPS的端口。由于使用HTTP的端口,因此TCP连接建立后的握手消息是基于HTTP的,由服务器判断这是一个HTTP协议,还是WebSocket协议。 WebSocket连接除了建立和关闭时的握手,数据传输和HTTP没丁点关系了。
历时11年,WebSocket终于被批准成为IETF的建议标准:RFC6455.其前身是WHATWG (Web Hypertext Application Technology Working Group)的工作。而Web Socket的API,是W3C的工作。
WebSocket可以只打开一个到服务器的链接,并且在此链接上交换信息。其优势在于减少了传统方法的复杂性,提高了可靠性和降低了浏览器和客户端之间的负载。这样做的一个重要原因是,很多防火墙屏蔽80以外的端口,迫使越来越多的应用迁移到HTTP上来了。
11年的websocket草案的变迁中,有的浏览器支持的是旧版本的websocket,比如iPhone4上的safari使用的WebSocket是旧版的握手协议,那么就要使用就的握手协议来制做服务器端。如今只有Safari支持旧版本的协议,Chrome和Firefox最新版都已升级至Hybi-10(协议地址)。因此,我们再来看一下WebSocket新版协议Hybi-10。这次协议变更非常大,主要集中在握手协议和数据传输的格式上。
我们先来看一下大致的区别:
最老的websocket草案标准中是没有安全key,草案7.5、7.6中有两个安全key,而现在的草案10中只有一个安全key,即将 7.5、7.6中http头中的”Sec-WebSocket-Key1″与”Sec-WebSocket-Key2″合并为了一个”Sec- WebSocket-Key”
把http头中Upgrade的值由”WebSocket”修改为了”websocket”;http头中的”-Origin”修改为了”Sec-WebSocket-Origin”;
增加了http头”Sec-WebSocket-Accept”,用来返回原来草案7.5、7.6服务器返回给客户端的握手验证,原来是以内容的形式返回,现在是放到了http头中;另外服务器返回客户端的验证方式也有变化。
服务器生成验证的方式变化较大,我们来做一介绍。
1 | GET / HTTP/1.1 |
旧版生成Token的方法如下:
取出Sec-WebSocket-Key1中的所有数字字符形成一个数值,这里是1427964708,然后除以Key1中的空格数目,得到一个数值,保留该数值整数位,得到数值N1;对Sec-WebSocket-Key2采取同样的算法,得到第二个整数N2;把N1和N2按照Big- Endian字符序列连接起来,然后再与另外一个Key3连接,得到一个原始序列ser_key。Key3是指在握手请求最后,有一个8字节的奇怪的字符串”;”######”,这个就是Key3。然后对ser_key进行一次md5运算得出一个16字节长的digest,这就是老版本协议需要的 token,然后将这个token附在握手消息的最后发送回Client,即可完成握手。
1 | GET / HTTP/1.1 |
新版生成Token的方法如下:
首先服务器将key(长度24)截取出来,如4tAjitqO9So2Wu8lkrsq3w==,用它和自定义的一个字符串(长度 36)258EAFA5-E914-47DA-95CA-C5AB0DC85B11连接起来,然后把这一字符串进行SHA-1算法加密,得到长度为20字节的二进制数据,再将这些数据经过Base64编码,最终得到服务端的密钥,也就是ser_key。服务器将ser_key附在返回值Sec- WebSocket-Accept后,至此握手成功。
WebSocket也有自己一套帧协议。数据报文格式如下:
1 | 0 1 2 3 |
FIN:1位,用来表明这是一个消息的最后的消息片断,当然第一个消息片断也可能是最后的一个消息片断;
RSV1, RSV2, RSV3: 分别都是1位,如果双方之间没有约定自定义协议,那么这几位的值都必须为0,否则必须断掉WebSocket连接;
Opcode:4位操作码,定义有效负载数据,如果收到了一个未知的操作码,连接也必须断掉,以下是定义的操作码:
%x0 表示连续消息片断
%x1 表示文本消息片断
%x2 表未二进制消息片断
%x3-7 为将来的非控制消息片断保留的操作码
%x8 表示连接关闭
%x9 表示心跳检查的ping
%xA 表示心跳检查的pong
%xB-F 为将来的控制消息片断的保留操作码
Mask:1位,定义传输的数据是否有加掩码,如果设置为1,掩码键必须放在masking-key区域,客户端发送给服务端的所有消息,此位的值都是1;
Payload length: 传输数据的长度,以字节的形式表示:7位、7+16位、或者7+64位。如果这个值以字节表示是0-125这个范围,那这个值就表示传输数据的长度;如果这个值是126,则随后的两个字节表示的是一个16进制无符号数,用来表示传输数据的长度;如果这个值是127,则随后的是8个字节表示的一个64位无符合数,这个数用来表示传输数据的长度。多字节长度的数量是以网络字节的顺序表示。负载数据的长度为扩展数据及应用数据之和,扩展数据的长度可能为0,因而此时负载数据的长度就为应用数据的长度。
Masking-key:0或4个字节,客户端发送给服务端的数据,都是通过内嵌的一个32位值作为掩码的;掩码键只有在掩码位设置为1的时候存在。
Payload data: (x+y)位,负载数据为扩展数据及应用数据长度之和。
Extension data:x位,如果客户端与服务端之间没有特殊约定,那么扩展数据的长度始终为0,任何的扩展都必须指定扩展数据的长度,或者长度的计算方式,以及在握手时如何确定正确的握手方式。如果存在扩展数据,则扩展数据就会包括在负载数据的长度之内。
Application data:y位,任意的应用数据,放在扩展数据之后,应用数据的长度=负载数据的长度-扩展数据的长度。
(Message Queuing Telemetry Transport,消息队列遥测传输)是轻量级基于代理的发布/订阅的消息传输协议,设计思想是开放、简单、轻量、易于实现。这些特点使它适用于受限环境。例如,但不仅限于此:
网络代价昂贵,带宽低、不可靠。
在嵌入设备中运行,处理器和内存资源有限。
该协议的特点有:
早在1999年,IBM的Andy Stanford-Clark博士以及Arcom公司ArlenNipper博士发明了MQTT(Message Queuing Telemetry Transport,消息队列遥测传输)技术。BM和St. Jude医疗中心通过MQTT开发了一套Merlin系统,该系统使用了用于家庭保健的传感器。St. Jude医疗中心设计了一个叫做Merlin@home的心脏装置,这种无限发射器可以用来监控那些已经植入复律-除颤器和起搏器(两者都是基本的传感器)的心脏病人。
该产品利用MQTT把病人的即时更新信息传给医生/医院,然后医院进行保存。这样的话,病人就不用亲自去医院检查心脏仪器了,医生可以随时查看病人的数据,给出建议,病人在家里就可以自行检查。
IBM称该发射器包括一个大型触摸屏,一个嵌入式键盘平台,以及一个Linux操作系统。
在未来几年,MQTT的应用会越来越广,值得关注。
通过MQTT协议,目前已经扩展出了数十个MQTT服务器端程序,可以通过PHP,JAVA,Python,C,C#等系统语言来向MQTT发送相关消息。
此外,国内很多企业都广泛使用MQTT作为Android手机客户端与服务器端推送消息的协议。其中Sohu,Cmstop手机客户端中均有使用到MQTT作为消息推送消息。据Cmstop主要负责消息推送的高级研发工程师李文凯称,随着移动互联网的发展,MQTT由于开放源代码,耗电量小等特点,将会在移动消息推送领域会有更多的贡献,在物联网领域,传感器与服务器的通信,信息的收集,MQTT都可以作为考虑的方案之一。在未来MQTT会进入到我们生活的各各方面。
如果需要下载MQTT服务器端,可以直接去MQTT官方网站点击software进行下载MQTT协议衍生出来的各个不同版本。
MQTT和TCP、WebSocket的关系可以用下图一目了然:
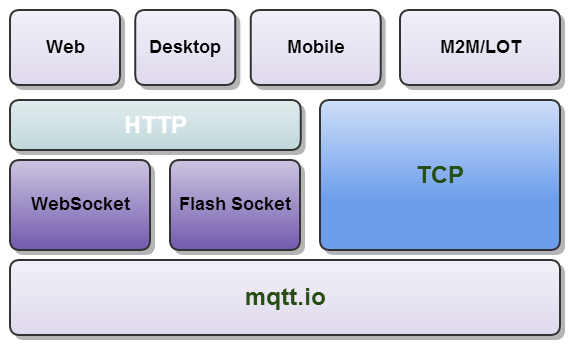
MQTT协议专注于网络、资源受限环境,建立之初不曾考虑WEB环境。HTML5 Websocket是建立在TCP基础上的双通道通信,和TCP通信方式很类似,适用于WEB浏览器环境。虽然MQTT基因层面选择了TCP作为通信通道,但我们添加个编解码方式,MQTT over Websocket也可以的。这样做的好处,MQTT的使用范畴被扩展到HTML5、桌面端浏览器、移动端WebApp、Hybrid等,多了一些想像空间。这样看来,无论是移动端,还是WEB端,MQTT都会有自己的使用空间。
In this article we’ll explore the asynchronous execution support in Spring – and the @Async annotation.
Simply put – annotating a method of a bean with @Async will make it execute in a separate thread i.e. the caller will not wait for the completion of the called method.
Let’s start by enabling asynchronous processing with Java configuration – by simply adding the @EnableAsync to a configuration class:
1 | @Configuration |
The enable annotation is enough, but as you’d expect, there are also a few simple options for configuration as well:
Asynchronous processing can also be enabled using XML configuration – by using the task namespace:
1 | <task:executor id="myexecutor" pool-size="5" /> |
First – let’s go over the rules – @Async has two limitations:
The reasons are simple – the method needs to be public so that it can be proxied. And self-invocation doesn’t work because it bypasses the proxy and calls the underlying method directly.
Following is the simple way to configure a method with void return type to run asynchronously:
1 | @Async |
@Async can also be applied to a method with return type – by wrapping the actual return in a Future:
1 | @Async |
Spring also provides a AsyncResult class which implements Future. This can be used to track the result of asynchronous method execution.
Now, let’s invoke the above method and retrieve the result of the asynchronous process using the Future object.
1 | public void testAsyncAnnotationForMethodsWithReturnType() |
By default Spring uses a SimpleAsyncTaskExecutor to actually run these methods asynchronously. The defaults can be overridden at two levels – at the application level or at the individual method level.
The required executor needs to be declared in a configuration class:
1 | @Configuration |
Then the executor name should be provided as an attribute in @Async:
1 | @Async("threadPoolTaskExecutor") |
The configuration class should implement the AsyncConfigurer interface – which will mean that it has the implement the getAsyncExecutor() method. It’s here that we will return the executor for the entire application – this now becomes the default executor to run methods annotated with @Async:
1 | @Configuration |
When a method return type is a Future, exception handling is easy – Future.get() method will throw the exception.
But, if the return type is void, exceptions will not be propagated to the calling thread. Hence we need to add extra configurations to handle exceptions.
We’ll create a custom async exception handler by implementing AsyncUncaughtExceptionHandler interface. The handleUncaughtException() method is invoked when there are any uncaught asynchronous exceptions:
1 | public class CustomAsyncExceptionHandler implements AsyncUncaughtExceptionHandler { |
In the previous section we looked at the AsyncConfigurer interface implemented by the configuration class. As part of that, we also need to override the getAsyncUncaughtExceptionHandler() method to return our custom asynchronous exception handler:
1 |
|
In this tutorial we looked at running asynchronous code with Spring. We started with the very basic configuration and annotation to make it work but also looked at more advanced configs such as providing our own executor, or exception handling strategies.
Kafka是一种分布式的,基于发布/订阅的消息系统。主要设计目标如下:
*以时间复杂度为O(1)的方式提供消息持久化能力,并保证即使对TB级以上数据也能保证常数时间的访问性能
*高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输
*支持Kafka Server间的消息分区,及分布式消息消费,同时保证每个partition内的消息顺序传输
*同时支持离线数据处理和实时数据处理
在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息队列在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束
有时在处理数据的时候处理过程会失败。除非数据被持久化,否则将永远丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失 风险。在被许多消息队列所采用的”插入-获取-删除”范式中,在把一个消息从队列中删除之前,需要你的处理过程明确的指出该消息已经被处理完毕,确保你的 数据被安全的保存直到你使用完毕。
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的;只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住增长的访问压力,而不是因为超出负荷的请求而完全崩溃。
当体系的一部分组件失效,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。而这种允许重试或者延后处理请求的能力通常是造就一个略感不便的用户和一个沮丧透顶的用户之间的区别。
消息队列提供的冗余机制保证了消息能被实际的处理,只要一个进程读取了该队列即可。在此基础上,IronMQ提供了一个”只送达一次”保证。无论有多少进 程在从队列中领取数据,每一个消息只能被处理一次。这之所以成为可能,是因为获取一个消息只是”预定”了这个消息,暂时把它移出了队列。除非客户端明确的 表示已经处理完了这个消息,否则这个消息会被放回队列中去,在一段可配置的时间之后可再次被处理。
在许多情况下,数据处理的顺序都很重要。消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。IronMO保证消息浆糊通过FIFO(先进先出)的顺序来处理,因此消息在队列中的位置就是从队列中检索他们的位置。
在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行—写入队列的处理会尽可能的快速,而不受从队列读的预备处理的约束。该缓冲有助于控制和优化数据流经过系统的速度。
在一个分布式系统里,要得到一个关于用户操作会用多长时间及其原因的总体印象,是个巨大的挑战。消息系列通过消息被处理的频率,来方便的辅助确定那些表现不佳的处理过程或领域,这些地方的数据流都不够优化。
很多时候,你不想也不需要立即处理消息。消息队列提供了异步处理机制,允许你把一个消息放入队列,但并不立即处理它。你想向队列中放入多少消息就放多少,然后在你乐意的时候再去处理它们。
RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发。同时实现了Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负 载均衡或者数据持久化都有很好的支持。
Redis是一个基于Key-Value对的NoSQL数据库,开发维护很活跃。虽然它是一个Key-Value数据库存储系统,但它本身支持MQ功能, 所以完全可以当做一个轻量级的队列服务来使用。对于RabbitMQ和Redis的入队和出队操作,各执行100万次,每10万次记录一次执行时间。测试 数据分为128Bytes、512Bytes、1K和10K四个不同大小的数据。实验表明:入队时,当数据比较小时Redis的性能要高于 RabbitMQ,而如果数据大小超过了10K,Redis则慢的无法忍受;出队时,无论数据大小,Redis都表现出非常好的性能,而RabbitMQ 的出队性能则远低于Redis。
ZeroMQ号称最快的消息队列系统,尤其针对大吞吐量的需求场景。ZMQ能够实现RabbitMQ不擅长的高级/复杂的队列,但是开发人员需要自己组合 多种技术框架,技术上的复杂度是对这MQ能够应用成功的挑战。ZeroMQ具有一个独特的非中间件的模式,你不需要安装和运行一个消息服务器或中间件,因 为你的应用程序将扮演了这个服务角色。你只需要简单的引用ZeroMQ程序库,可以使用NuGet安装,然后你就可以愉快的在应用程序之间发送消息了。但 是ZeroMQ仅提供非持久性的队列,也就是说如果down机,数据将会丢失。其中,Twitter的Storm中默认使用ZeroMQ作为数据流的传 输。
ActiveMQ是Apache下的一个子项目。 类似于ZeroMQ,它能够以代理人和点对点的技术实现队列。同时类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。
Kafka是Apache下的一个子项目,是一个高性能跨语言分布式Publish/Subscribe消息队列系统,而Jafka是在Kafka之上孵 化而来的,即Kafka的一个升级版。具有以下特性:快速持久化,可以在O(1)的系统开销下进行消息持久化;高吞吐,在一台普通的服务器上既可以达到 10W/s的吞吐速率;完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现复杂均衡;支持Hadoop 数据并行加载,对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka通过Hadoop的并行 加载机制来统一了在线和离线的消息处理,这一点也是本课题所研究系统所看重的。Apache Kafka相对于ActiveMQ是一个非常轻量级的消息系统,除了性能非常好之外,还是一个工作良好的分布式系统。
Kafka集群包含一个或多个服务器,这种服务器被称为broker
每条发布到Kafka集群的消息都有一个类别,这个类别被称为topic。(物理上不同topic的消息分开存储,逻辑上一个topic的消息虽然保存于一个或多个broker上但用户只需指定消息的topic即可生产或消费数据而不必关心数据存于何处)
parition是物理上的概念,每个topic包含一个或多个partition,创建topic时可指定parition数量。每个partition对应于一个文件夹,该文件夹下存储该partition的数据和索引文件
负责发布消息到Kafka broker
消费消息。每个consumer属于一个特定的consuer group(可为每个consumer指定group name,若不指定group name则属于默认的group)。使用consumer high level API时,同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。
<img src="/files/0924-1.jpg">
如上图所示,一个典型的kafka集群中包含若干producer(可以是web前端产生的page view,或者是服务器日志,系统CPU、memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高), 若干consumer group,以及一个Zookeeper集 群。Kafka通过Zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。producer使用push模式将消息发布到broker,consumer使用pull模式从 broker订阅并消费消息。
作为一个messaging system,Kafka遵循了传统的方式,选择由producer向broker push消息并由consumer从broker pull消息。一些logging-centric system,比如Facebook的Scribe和Cloudera的Flume,采用非常不同的push模式。事实上,push模式和pull模式各有优劣。
push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造 成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
Topic在逻辑上可以被认为是一个在的queue,每条消费都必须指定它的topic,可以简单理解为必须指明把这条消息放进哪个queue里。 为了使得Kafka的吞吐率可以水平扩展,物理上把topic分成一个或多个partition,每个partition在物理上对应一个文件夹,该文件 夹下存储这个partition的所有消息和索引文件。
<img src="/files/0924-2.jpg">
每个日志文件都是“log entries”序列,每一个log entry包含一个4字节整型数(值为N),其后跟N个字节的消息体。每条消息都有一个当前partition下唯一的64字节的offset,它指明了这条消息的起始位置。磁盘上存储的消费格式如下:
message length : 4 bytes (value: 1+4+n)
“magic” value : 1 byte
crc : 4 bytes
payload : n bytes
这个“log entries”并非由一个文件构成,而是分成多个segment,每个segment名为该segment第一条消息的offset和“.kafka”组成。另外会有一个索引文件,它标明了每个segment下包含的log entry的offset范围,如下图所示。
<img src="/files/0924-3.jpg">
因为每条消息都被append到该partition中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
<img src="/files/0924-4.jpg">
每一条消息被发送到broker时,会根据paritition规则选择被存储到哪一个partition。如果partition规则设置的合理,所有 消息可以均匀分布到不同的partition里,这样就实现了水平扩展。(如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个 topic的性能瓶颈,而partition解决了这个问题)。在创建topic时可以在$KAFKA_HOME/config/server.properties中指定这个partition的数量(如下所示),当然也可以在topic创建之后去修改parition数量。
1 | # The default number of log partitions per topic. More partitions allow greater |
在发送一条消息时,可以指定这条消息的key,producer根据这个key和partition机制来判断将这条消息发送到哪个parition。 paritition机制可以通过指定producer的paritition. class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。本例中如果key可以被解析为整数则将对应的整数与partition总数取余,该消息会被发送到该数对应的partition。(每个parition都会有个序号)
1 | import kafka.producer.Partitioner; |
如果将上例中的class作为partition.class,并通过如下代码发送20条消息(key分别为0,1,2,3)至topic2(包含4个partition)。
1 | public void sendMessage() throws InterruptedException{ |
则key相同的消息会被发送并存储到同一个partition里,而且key的序号正好和partition序号相同。(partition序号从0开始,本例中的key也正好从0开始)。如下图所示。
<img src="/files/0924-5.jpg">
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据(实际 上也没必要),因此Kafka提供两种策略去删除旧数据。一是基于时间,二是基于partition文件大小。例如可以通过配置$KAFKA_HOME/config/server.properties,让Kafka删除一周前的数据,也可通过配置让Kafka在partition文件超过1GB时删除旧数据,如下所示。
1 | ############################# Log Retention Policy ############################# |
这里要注意,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除文件与Kafka性能无关,选择怎样的删除策略只 与磁盘以及具体的需求有关。另外,Kafka会为每一个consumer group保留一些metadata信息—当前消费的消息的position,也即offset。这个offset由consumer控制。正常情况下 consumer会在消费完一条消息后线性增加这个offset。当然,consumer也可将offset设成一个较小的值,重新消费一些消息。因为 offet由consumer控制,所以Kafka broker是无状态的,它不需要标记哪些消息被哪些consumer过,不需要通过broker去保证同一个consumer group只有一个consumer能消费某一条消息,因此也就不需要锁机制,这也为Kafka的高吞吐率提供了有力保障。
Kafka从0.8开始提供partition级别的replication,replication的数量可在$KAFKA_HOME/config/server.properties中配置。
1 | default.replication.factor = 1 |
该 Replication与leader election配合提供了自动的failover机制。replication对Kafka的吞吐率是有一定影响的,但极大的增强了可用性。默认情况 下,Kafka的replication数量为1。 每个partition都有一个唯一的leader,所有的读写操作都在leader上完 成,leader批量从leader上pull数据。一般情况下partition的数量大于等于broker的数量,并且所有partition的 leader均匀分布在broker上。follower上的日志和其leader上的完全一样。
和大部分分布式系统一样,Kakfa处理失败需要明确定义一个broker是否alive。对于Kafka而言,Kafka存活包含两个条件,一是它必须 维护与Zookeeper的session(这个通过Zookeeper的heartbeat机制来实现)。二是follower必须能够及时将 leader的writing复制过来,不能“落后太多”。
leader会track“in sync”的node list。如果一个follower宕机,或者落后太多,leader将把它从”in sync” list中移除。这里所描述的“落后太多”指follower复制的消息落后于leader后的条数超过预定值,该值可在$KAFKA_HOME/config/server.properties中配置
1 | #If a replica falls more than this many messages behind the leader, the leader will remove the follower from ISR and treat it as dead |
需要说明的是,Kafka只解决”fail/recover”,不处理“Byzantine”(“拜占庭”)问题。
一条消息只有被“in sync” list里的所有follower都从leader复制过去才会被认为已提交。这样就避免了部分数据被写进了leader,还没来得及被任何 follower复制就宕机了,而造成数据丢失(consumer无法消费这些数据)。而对于producer而言,它可以选择是否等待消息 commit,这可以通过request.required.acks来设置。这种机制确保了只要“in sync” list有一个或以上的flollower,一条被commit的消息就不会丢失。
这里的复制机制即不是同步复制,也不是单纯的异步复制。事实上,同步复制要求“活着的”follower都复制完,这条消息才会被认为commit,这种 复制方式极大的影响了吞吐率(高吞吐率是Kafka非常重要的一个特性)。而异步复制方式下,follower异步的从leader复制数据,数据只要被 leader写入log就被认为已经commit,这种情况下如果follwer都落后于leader,而leader突然宕机,则会丢失数据。而 Kafka的这种使用“in sync” list的方式则很好的均衡了确保数据不丢失以及吞吐率。follower可以批量的从leader复制数据,这样极大的提高复制性能(批量写磁盘),极 大减少了follower与leader的差距(前文有说到,只要follower落后leader不太远,则被认为在“in sync” list里)。
上文说明了Kafka是如何做replication的,另外一个很重要的问题是当leader宕机了,怎样在follower中选举出新的 leader。因为follower可能落后许多或者crash了,所以必须确保选择“最新”的follower作为新的leader。一个基本的原则就 是,如果leader不在了,新的leader必须拥有原来的leader commit的所有消息。这就需要作一个折衷,如果leader在标明一条消息被commit前等待更多的follower确认,那在它die之后就有更 多的follower可以作为新的leader,但这也会造成吞吐率的下降。
一种非常常用的选举leader的方式是“majority 灵秀”(“少数服从多数”),但Kafka并未采用这种方式。这种模式下,如果我们有2f+1个replica(包含leader和follower), 那在commit之前必须保证有f+1个replica复制完消息,为了保证正确选出新的leader,fail的replica不能超过f个。因为在剩 下的任意f+1个replica里,至少有一个replica包含有最新的所有消息。这种方式有个很大的优势,系统的latency只取决于最快的几台 server,也就是说,如果replication factor是3,那latency就取决于最快的那个follower而非最慢那个。majority vote也有一些劣势,为了保证leader election的正常进行,它所能容忍的fail的follower个数比较少。如果要容忍1个follower挂掉,必须要有3个以上的 replica,如果要容忍2个follower挂掉,必须要有5个以上的replica。也就是说,在生产环境下为了保证较高的容错程度,必须要有大量 的replica,而大量的replica又会在大数据量下导致性能的急剧下降。这就是这种算法更多用在Zookeeper这种共享集群配置的系统中而很少在需要存储大量数据的系统中使用的原因。例如HDFS的HA feature是基于majority-vote-based journal,但是它的数据存储并没有使用这种expensive的方式。
实际上,leader election算法非常多,比如Zookeper的Zab, Raft和Viewstamped Replication。而Kafka所使用的leader election算法更像微软的PacificA算法。
Kafka在Zookeeper中动态维护了一个ISR(in-sync replicas) set,这个set里的所有replica都跟上了leader,只有ISR里的成员才有被选为leader的可能。在这种模式下,对于f+1个 replica,一个Kafka topic能在保证不丢失已经ommit的消息的前提下容忍f个replica的失败。在大多数使用场景中,这种模式是非常有利的。事实上,为了容忍f个 replica的失败,majority vote和ISR在commit前需要等待的replica数量是一样的,但是ISR需要的总的replica的个数几乎是majority vote的一半。
虽然majority vote与ISR相比有不需等待最慢的server这一优势,但是Kafka作者认为Kafka可以通过producer选择是否被commit阻塞来改善这一问题,并且节省下来的replica和磁盘使得ISR模式仍然值得。
上文提到,在ISR中至少有一个follower时,Kafka可以确保已经commit的数据不丢失,但如果某一个partition的所有replica都挂了,就无法保证数据不丢失了。这种情况下有两种可行的方案:
* 等待ISR中的任一个replica“活”过来,并且选它作为leader
* 选择第一个“活”过来的replica(不一定是ISR中的)作为leader
这就需要在可用性和一致性当中作出一个简单的平衡。如果一定要等待ISR中的replica“活”过来,那不可用的时间就可能会相对较长。而且如果 ISR中的所有replica都无法“活”过来了,或者数据都丢失了,这个partition将永远不可用。选择第一个“活”过来的replica作为 leader,而这个replica不是ISR中的replica,那即使它并不保证已经包含了所有已commit的消息,它也会成为leader而作为 consumer的数据源(前文有说明,所有读写都由leader完成)。Kafka0.8.*使用了第二种方式。根据Kafka的文档,在以后的版本 中,Kafka支持用户通过配置选择这两种方式中的一种,从而根据不同的使用场景选择高可用性还是强一致性。
上文说明了一个parition的replication过程,然尔Kafka集群需要管理成百上千个partition,Kafka通过 round-robin的方式来平衡partition从而避免大量partition集中在了少数几个节点上。同时Kafka也需要平衡leader的 分布,尽可能的让所有partition的leader均匀分布在不同broker上。另一方面,优化leadership election的过程也是很重要的,毕竟这段时间相应的partition处于不可用状态。一种简单的实现是暂停宕机的broker上的所有 partition,并为之选举leader。实际上,Kafka选举一个broker作为controller,这个controller通过 watch Zookeeper检测所有的broker failure,并负责为所有受影响的parition选举leader,再将相应的leader调整命令发送至受影响的broker,过程如下图所示。
<img src="/files/0924-6.jpg">
这样做的好处是,可以批量的通知leadership的变化,从而使得选举过程成本更低,尤其对大量的partition而言。如果controller 失败了,幸存的所有broker都会尝试在Zookeeper中创建/controller->{this broker id},如果创建成功(只可能有一个创建成功),则该broker会成为controller,若创建不成功,则该broker会等待新 controller的命令。
<img src="/files/0924-7.jpg">
(本节所有描述都是基于consumer hight level API而非low level API)。
每一个consumer实例都属于一个consumer group,每一条消息只会被同一个consumer group里的一个consumer实例消费。(不同consumer group可以同时消费同一条消息)
<img src="/files/0924-8.jpg">
很多传统的message queue都会在消息被消费完后将消息删除,一方面避免重复消费,另一方面可以保证queue的长度比较少,提高效率。而如上文所将,Kafka并不删除 已消费的消息,为了实现传统message queue消息只被消费一次的语义,Kafka保证保证同一个consumer group里只有一个consumer会消费一条消息。与传统message queue不同的是,Kafka还允许不同consumer group同时消费同一条消息,这一特性可以为消息的多元化处理提供了支持。实际上,Kafka的设计理念之一就是同时提供离线处理和实时处理。根据这一 特性,可以使用Storm这种实时流处理系统对消息进行实时在线处理,同时使用Hadoop这种批处理系统进行离线处理,还可以同时将数据实时备份到另一 个数据中心,只需要保证这三个操作所使用的consumer在不同的consumer group即可。下图展示了Kafka在Linkedin的一种简化部署。
<img src="/files/0924-9.jpg">
为了更清晰展示Kafka consumer group的特性,笔者作了一项测试。创建一个topic (名为topic1),创建一个属于group1的consumer实例,并创建三个属于group2的consumer实例,然后通过producer 向topic1发送key分别为1,2,3r的消息。结果发现属于group1的consumer收到了所有的这三条消息,同时group2中的3个 consumer分别收到了key为1,2,3的消息。如下图所示。
<img src="/files/0924-10.jpg">
(本节所讲述内容均基于Kafka consumer high level API)
Kafka保证同一consumer group中只有一个consumer会消息某条消息,实际上,Kafka保证的是稳定状态下每一个consumer实例只会消费某一个或多个特定 partition的数据,而某个partition的数据只会被某一个特定的consumer实例所消费。这样设计的劣势是无法让同一个 consumer group里的consumer均匀消费数据,优势是每个consumer不用都跟大量的broker通信,减少通信开销,同时也降低了分配难度,实现也 更简单。另外,因为同一个partition里的数据是有序的,这种设计可以保证每个partition里的数据也是有序被消费。
如果某consumer group中consumer数量少于partition数量,则至少有一个consumer会消费多个partition的数据,如果consumer 的数量与partition数量相同,则正好一个consumer消费一个partition的数据,而如果consumer的数量多于 partition的数量时,会有部分consumer无法消费该topic下任何一条消息。
如下例所示,如果topic1有0,1,2共三个partition,当group1只有一个consumer(名为consumer1)时,该 consumer可消费这3个partition的所有数据。
<img src="/files/0924-11.jpg">
增加一个consumer(consumer2)后,其中一个consumer(consumer1)可消费2个partition的数据,另外一个consumer(consumer2)可消费另外一个partition的数据。
<img src="/files/0924-12.jpg">
再增加一个consumer(consumer3)后,每个consumer可消费一个partition的数据。consumer1消费partition0,consumer2消费partition1,consumer3消费partition2
<img src="/files/0924-13.jpg">
再增加一个consumer(consumer4)后,其中3个consumer可分别消费一个partition的数据,另外一个consumer(consumer4)不能消费topic1任何数据。
<img src="/files/0924-14.jpg">
此时关闭consumer1,剩下的consumer可分别消费一个partition的数据。
<img src="/files/0924-15.jpg">
接着关闭consumer2,剩下的consumer3可消费2个partition,consumer4可消费1个partition。
<img src="/files/0924-16.jpg">
再关闭consumer3,剩下的consumer4可同时消费topic1的3个partition。
<img src="/files/0924-17.jpg">
consumer rebalance算法如下:
* Sort PT (all partitions in topic T)
* Sort CG(all consumers in consumer group G)
* Let i be the index position of Ci in CG and let N=size(PT)/size(CG)
* Remove current entries owned by Ci from the partition owner registry
* Assign partitions from iN to (i+1)N-1 to consumer Ci
* Add newly assigned partitions to the partition owner registry
目前consumer rebalance的控制策略是由每一个consumer通过Zookeeper完成的。具体的控制方式如下:
* Register itself in the consumer id registry under its group.
* Register a watch on changes under the consumer id registry.
* Register a watch on changes under the broker id registry.
* If the consumer creates a message stream using a topic filter, it also registers a watch on changes under the broker topic registry.
* Force itself to rebalance within in its consumer group.在这种策略下,每一个consumer或者broker的增加或者减少都会触发consumer rebalance。因为每个consumer只负责调整自己所消费的partition,为了保证整个consumer group的一致性,所以当一个consumer触发了rebalance时,该consumer group内的其它所有consumer也应该同时触发rebalance。
目前(2015-01-19)最新版(0.8.2)Kafka采用的是上述方式。
但该方式有不利的方面:
* Herd effect : 任何broker或者consumer的增减都会触发所有的consumer的rebalance
* Split Brain : 每个consumer分别单独通过Zookeeper判断哪些partition down了,那么不同consumer从Zookeeper“看”到的view就可能不一样,这就会造成错误的reblance尝试。而且有可能所有的 consumer都认为rebalance已经完成了,但实际上可能并非如此。
根据Kafka官方文档,Kafka作者正在考虑在还未发布的0.9.x版本中使用中心协调器(coordinator)。 大体思想是选举出一个broker作为coordinator,由它watch Zookeeper,从而判断是否有partition或者consumer的增减,然后生成rebalance命令,并检查是否这些rebalance 在所有相关的consumer中被执行成功,如果不成功则重试,若成功则认为此次rebalance成功(这个过程跟replication controller非常类似,所以我很奇怪为什么当初设计replication controller时没有使用类似方式来解决consumer rebalance的问题)。流程如下:
<img src="/files/0924-18.jpg">
通过上文介绍,想必读者已经明天了producer和consumer是如何工作的,以及Kafka是如何做replication的,接下来要讨 论的是Kafka如何确保消息在producer和consumer之间传输。有这么几种可能的delivery guarantee:
Exactly once 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户所想要的。Kafka的delivery guarantee semantic非常直接。当producer向broker发送消息时,一旦这条消息被commit,因数replication的存在,它就不会丢。 但是如果producer发送数据给broker后,遇到的网络问题而造成通信中断,那producer就无法判断该条消息是否已经commit。这一点 有点像向一个自动生成primary key的数据库表中插入数据。虽然Kafka无法确定网络故障期间发生了什么,但是producer可以生成一种类似于primary key的东西,发生故障时幂等性的retry多次,这样就做到了Exactly one。截止到目前(Kafka 0.8.2版本,2015-01-25),这一feature还并未实现,有希望在Kafka未来的版本中实现。(所以目前默认情况下一条消息从producer和broker是确保了At least once,但可通过设置producer异步发送实现At most once)。
接下来讨论的是消息从broker到consumer的delivery guarantee semantic。(仅针对Kafka consumer high level API)。consumer在从broker读取消息后,可以选择commit,该操作会在Zookeeper中存下该consumer在该 partition下读取的消息的offset。该consumer下一次再读该partition时会从下一条开始读取。如未commit,下一次读取 的开始位置会跟上一次commit之后的开始位置相同。当然可以将consumer设置为autocommit,即consumer一旦读到数据立即自动 commit。如果只讨论这一读取消息的过程,那Kafka是确保了Exactly once。但实际上实际使用中consumer并非读取完数据就结束了,而是要进行进一步处理,而数据处理与commit的顺序在很大程度上决定了消息从broker和consumer的delivery guarantee semantic。
读完消息先commit再处理消息。这种模式下,如果consumer在commit后还没来得及处理消息就crash了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于At most once
如果一定要做到Exactly once,就需要协调offset和实际操作的输出。精典的做法是引入两阶段提交。如 果能让offset和操作输入存在同一个地方,会更简洁和通用。这种方式可能更好,因为许多输出系统可能不支持两阶段提交。比如,consumer拿到数 据后可能把数据放到HDFS,如果把最新的offset和数据本身一起写到HDFS,那就可以保证数据的输出和offset的更新要么都完成,要么都不完 成,间接实现Exactly once。(目前就high level API而言,offset是存于Zookeeper中的,无法存于HDFS,而low level API的offset是由自己去维护的,可以将之存于HDFS中)
总之,Kafka默认保证At least once,并且允许通过设置producer异步提交来实现At most once。而Exactly once要求与目标存储系统协作,幸运的是Kafka提供的offset可以使用这种方式非常直接非常容易。
纸上得来终觉浅,绝知些事要躬行。笔者希望能亲自测一下Kafka的性能,而非从网上找一些测试数据。所以笔者曾在0.8发布前两个月做过详细的Kafka0.8性能测试,不过很可惜测试报告不慎丢失。所幸在网上找到了Kafka的创始人之一的Jay Kreps的bechmark。以下描述皆基于该benchmark。(该benchmark基于Kafka0.8.1)
该benchmark用到了六台机器,机器配置如下
该项测试只测producer的吞吐率,也就是数据只被持久化,没有consumer读数据。
在这一测试中,创建了一个包含6个partition且没有replication的topic。然后通过一个线程尽可能快的生成50 million条比较短(payload100字节长)的消息。测试结果是821,557 records/second(78.3MB/second)。
之所以使用短消息,是因为对于消息系统来说这种使用场景更难。因为如果使用MB/second来表征吞吐率,那发送长消息无疑能使得测试结果更好。
整个测试中,都是用每秒钟delivery的消息的数量乘以payload的长度来计算MB/second的,没有把消息的元信息算在内,所以实际的网络 使用量会比这个大。对于本测试来说,每次还需传输额外的22个字节,包括一个可选的key,消息长度描述,CRC等。另外,还包含一些请求相关的 overhead,比如topic,partition,acknowledgement等。这就导致我们比较难判断是否已经达到网卡极限,但是把这些 overhead都算在吞吐率里面应该更合理一些。因此,我们已经基本达到了网卡的极限。
初步观察此结果会认为它比人们所预期的要高很多,尤其当考虑到Kafka要把数据持久化到磁盘当中。实际上,如果使用随机访问数据系统,比如RDBMS, 或者key-velue store,可预期的最高访问频率大概是5000到50000个请求每秒,这和一个好的RPC层所能接受的远程请求量差不多。而该测试中远超于此的原因有 两个。
* Kafka确保写磁盘的过程是线性磁盘I/O,测试中使用的6块廉价磁盘线性I/O的最大吞吐量是822MB/second,这已经远大于1Gb 网卡所能带来的吞吐量了。许多消息系统把数据持久化到磁盘当成是一个开销很大的事情,这是因为他们对磁盘的操作都不是线性I/O。
* 在每一个阶段,Kafka都尽量使用批量处理。如果想了解批处理在I/O操作中的重要性,可以参考David Patterson的”Latency Lags Bandwidth“
该项测试与上一测试基本一样,唯一的区别是每个partition有3个replica(所以网络传输的和写入磁盘的总的数据量增加了3倍)。每一 个broker即要写作为leader的partition,也要读(从leader读数据)写(将数据写到磁盘)作为follower的 partition。测试结果为786,980 records/second(75.1MB/second)。
该项测试中replication是异步的,也就是说broker收到数据并写入本地磁盘后就acknowledge producer,而不必等所有replica都完成replication。也就是说,如果leader crash了,可能会丢掉一些最新的还未备份的数据。但这也会让message acknowledgement延迟更少,实时性更好。
这项测试说明,replication可以很快。整个集群的写能力可能会由于3倍的replication而只有原来的三分之一,但是对于每一个producer来说吞吐率依然足够好。
该项测试与上一测试的唯一区别是replication是同步的,每条消息只有在被in sync集合里的所有replica都复制过去后才会被置为committed(此时broker会向producer发送acknowledgement)。在这种模式下,Kafka可以保证即使leader crash了,也不会有数据丢失。测试结果为421,823 records/second(40.2MB/second)。
Kafka同步复制与异步复制并没有本质的不同。leader会始终track follower replica从而监控它们是否还alive,只有所有in sync集合里的replica都acknowledge的消息才可能被consumer所消费。而对follower的等待影响了吞吐率。可以通过增大batch size来改善这种情况,但为了避免特定的优化而影响测试结果的可比性,本次测试并没有做这种调整。
该测试相当于把上文中的1个producer,复制到了3台不同的机器上(在1台机器上跑多个实例对吞吐率的增加不会有太大帮忙,因为网卡已经基本饱和了),这3个producer同时发送数据。整个集群的吞吐率为2,024,032 records/second(193,0MB/second)。
消息系统的一个潜在的危险是当数据能都存于内存时性能很好,但当数据量太大无法完全存于内存中时(然后很多消息系统都会删除已经被消费的数据,但当 消费速度比生产速度慢时,仍会造成数据的堆积),数据会被转移到磁盘,从而使得吞吐率下降,这又反过来造成系统无法及时接收数据。这样就非常糟糕,而实际 上很多情景下使用queue的目的就是解决数据消费速度和生产速度不一致的问题。
但Kafka不存在这一问题,因为Kafka始终以O(1)的时间复杂度将数据持久化到磁盘,所以其吞吐率不受磁盘上所存储的数据量的影响。为了验证这一特性,做了一个长时间的大数据量的测试,下图是吞吐率与数据量大小的关系图。
<img src="/files/0924-19.jpg">
上图中有一些variance的存在,并可以明显看到,吞吐率并不受磁盘上所存数据量大小的影响。实际上从上图可以看到,当磁盘数据量达到1TB时,吞吐率和磁盘数据只有几百MB时没有明显区别。
这个variance是由Linux I/O管理造成的,它会把数据缓存起来再批量flush。上图的测试结果是在生产环境中对Kafka集群做了些tuning后得到的,这些tuning方法可参考这里。
需要注意的是,replication factor并不会影响consumer的吞吐率测试,因为consumer只会从每个partition的leader读数据,而与 replicaiton factor无关。同样,consumer吞吐率也与同步复制还是异步复制无关。
该测试从有6个partition,3个replication的topic消费50 million的消息。测试结果为940,521 records/second(89.7MB/second)。
可以看到,Kafkar的consumer是非常高效的。它直接从broker的文件系统里读取文件块。Kafka使用sendfile API来直接通过操作系统直接传输,而不用把数据拷贝到用户空间。该项测试实际上从log的起始处开始读数据,所以它做了真实的I/O。在生产环境下,consumer可以直接读取producer刚刚写下的数据(它可能还在缓存中)。实际上,如果在生产环境下跑I/O stat,你可以看到基本上没有物理“读”。也就是说生产环境下consumer的吞吐率会比该项测试中的要高。
将上面的consumer复制到3台不同的机器上,并且并行运行它们(从同一个topic上消费数据)。测试结果为2,615,968 records/second(249.5MB/second)。
正如所预期的那样,consumer的吞吐率几乎线性增涨。
上面的测试只是把producer和consumer分开测试,而该项测试同时运行producer和consumer,这更接近使用场景。实际上目前的replication系统中follower就相当于consumer在工作。
该项测试,在具有6个partition和3个replica的topic上同时使用1个producer和1个consumer,并且使用异步复制。测试结果为795,064 records/second(75.8MB/second)。
可以看到,该项测试结果与单独测试1个producer时的结果几乎一致。所以说consumer非常轻量级。
上面的所有测试都基于短消息(payload 100字节),而正如上文所说,短消息对Kafka来说是更难处理的使用方式,可以预期,随着消息长度的增大,records/second会减小,但 MB/second会有所提高。下图是records/second与消息长度的关系图。
<img src="/files/0924-20.jpg">
正如我们所预期的那样,随着消息长度的增加,每秒钟所能发送的消息的数量逐渐减小。但是如果看每秒钟发送的消息的总大小,它会随着消息长度的增加而增加,如下图所示。
<img src="/files/0924-21.jpg">
从上图可以看出,当消息长度为10字节时,因为要频繁入队,花了太多时间获取锁,CPU成了瓶颈,并不能充分利用带宽。但从100字节开始,我们可以看到带宽的使用逐渐趋于饱和(虽然MB/second还是会随着消息长度的增加而增加,但增加的幅度也越来越小)。
上文中讨论了吞吐率,那消息传输的latency如何呢?也就是说消息从producer到consumer需要多少时间呢?该项测试创建1个producer和1个consumer并反复计时。结果是,2 ms (median), 3ms (99th percentile, 14ms (99.9th percentile)。
(这里并没有说明topic有多少个partition,也没有说明有多少个replica,replication是同步还是异步。实际上这会极大影响 producer发送的消息被commit的latency,而只有committed的消息才能被consumer所消费,所以它会最终影响端到端的 latency)
如果读者想要在自己的机器上重现本次benchmark测试,可以参考本次测试的配置和所使用的命令。
实际上Kafka Distribution提供了producer性能测试工具,可通过bin/kafka-producer-perf-test.sh脚本来启动。所使用的命令如下
1 | Producer |
broker配置如下:
1 | ############################# Server Basics ############################# |